







前言:
很久以前就写好了字符串搜索的几个经典算法:KMP算法、Boyer-Moore算法以及Rabin-Karp算法。但是一直没有时间写,这次我准备详细的写一下KMP算法,简略的分析下BoyerMoore算法。
原理:
KMP算法:
KMP算法是一种子字符串查找算法,它将会返回目标子字符串在文本中的下标,相比暴力检索算法KMP算法拥有更好的时间复杂度。KMP算法的基本思想
是当字符串出现不匹配的时候,我们就已经知道了一部分的文本内容(即前面以及进行过匹配的文本),我们可以利用这些信息避免检索指针多余的倒退。比如当我们在检索文本"ABABC"中是否存在ABC时,我们检索到第二个"A"时会因为不匹配而停止,若是暴力检索算法,我们会从"B"继续开始检索,但这实际上是没有必要的,因为第一次检索后我们已近直到第二个字符为"B",它并不会进行匹配,所以KMP算法会跳过第二个字符"B"直接从第三个字符"A"开始检索。如图一所示,其中颜色方框表示出现了文本的不匹配。
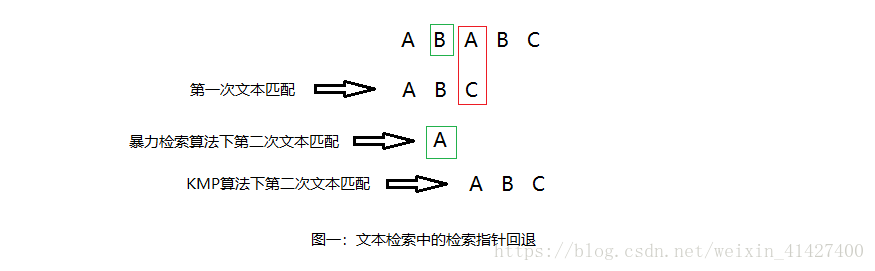
通过上图,我们可以发现KMP算法可以根据之前的信息,避免文本指针不必要的回退,而要完成这个工作我们最好的方法是使用
确定有限状态自动机(DFA)来完成这个工作。
DFA模拟:
对于KMP算法来说,我们将根据DFA所提供的信息,来完成文本指针的回退。对于每一个文本,它有其确定的一个状态机,如对于"ABABAC"其状态机如图二所示。
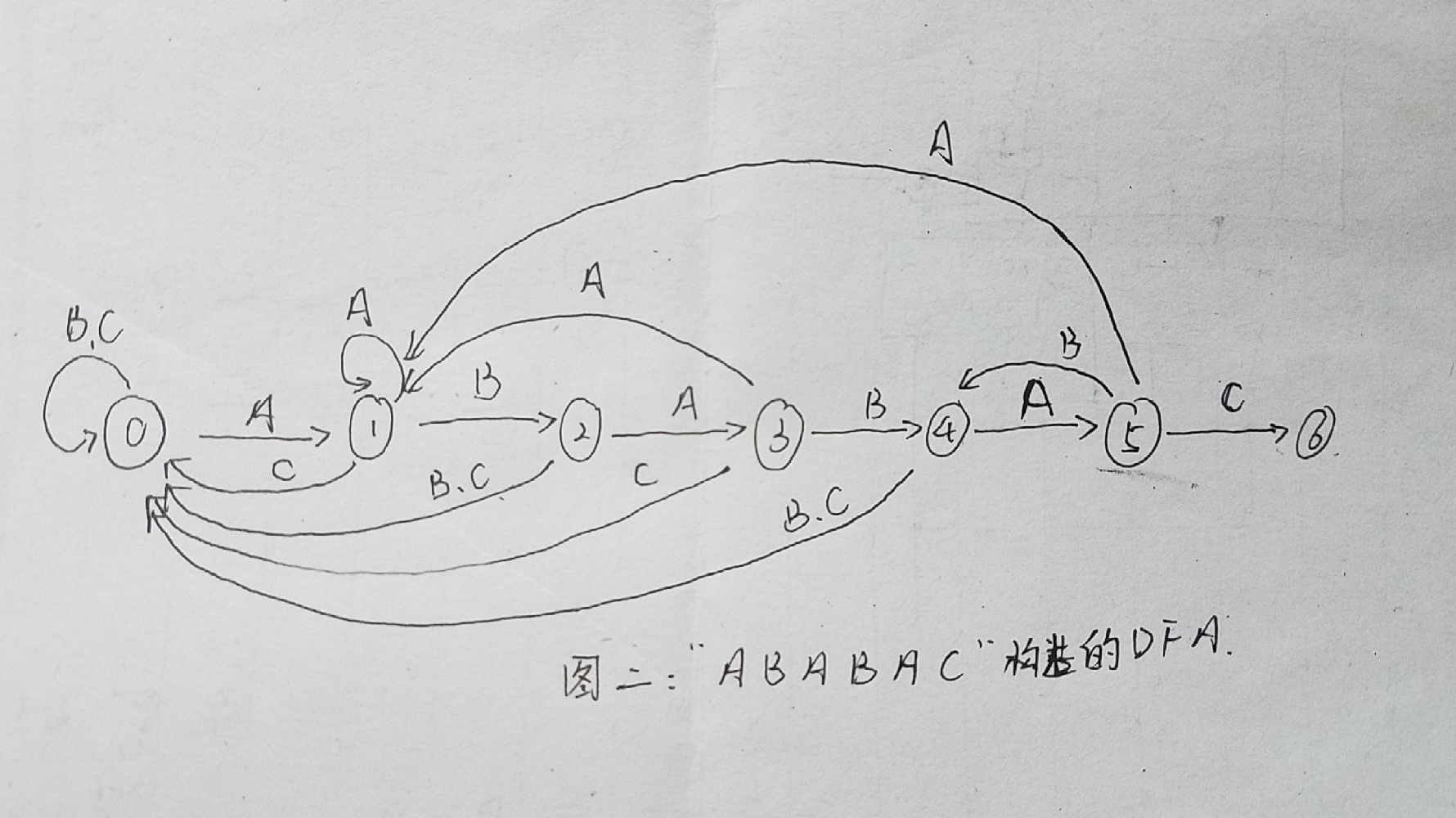
而在实际代码中,我们将用二维数组dfa[R][j]来储存状态机(如图三所示),其中R为字典中字符个数,j为模式字符串的长度。

当我们拥有了这个DFA以后,我们即可以开始从文本"ACABABAC"中检索"ABABAC"字符串,当我们在文本中进行检索时,我们将从文本的开头进行检索,同时构造DFA,并使其DFA进入状态0,
我们将依次遍历整个文本,并根据我们检索到的字符来变换状态机的状态,当我们进入6状态后,即完成文本的匹配;若文本检索完成后,仍未进入状态6那么则表示文本中没有相应的子字符串。(如图四所示)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 68
68











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









